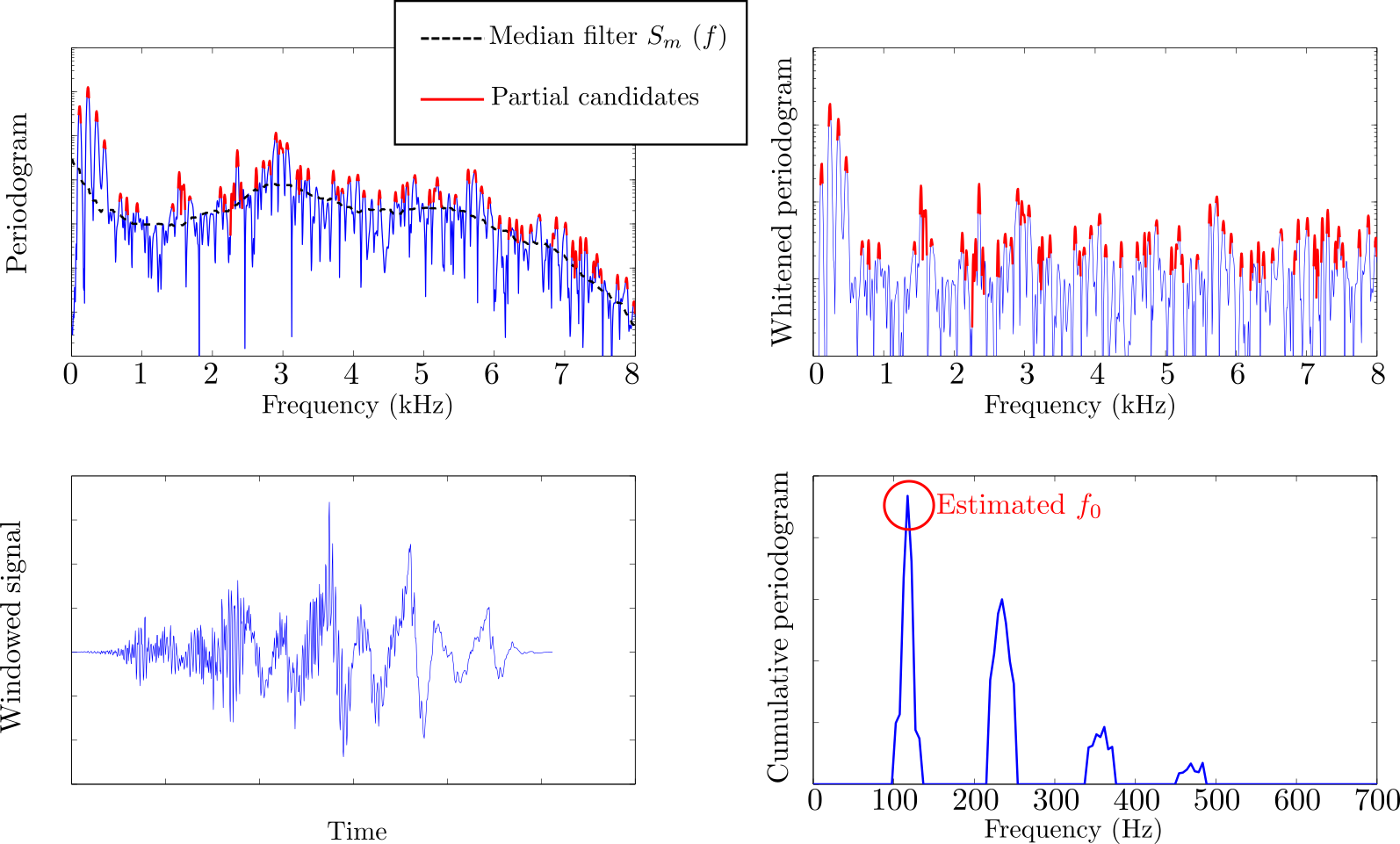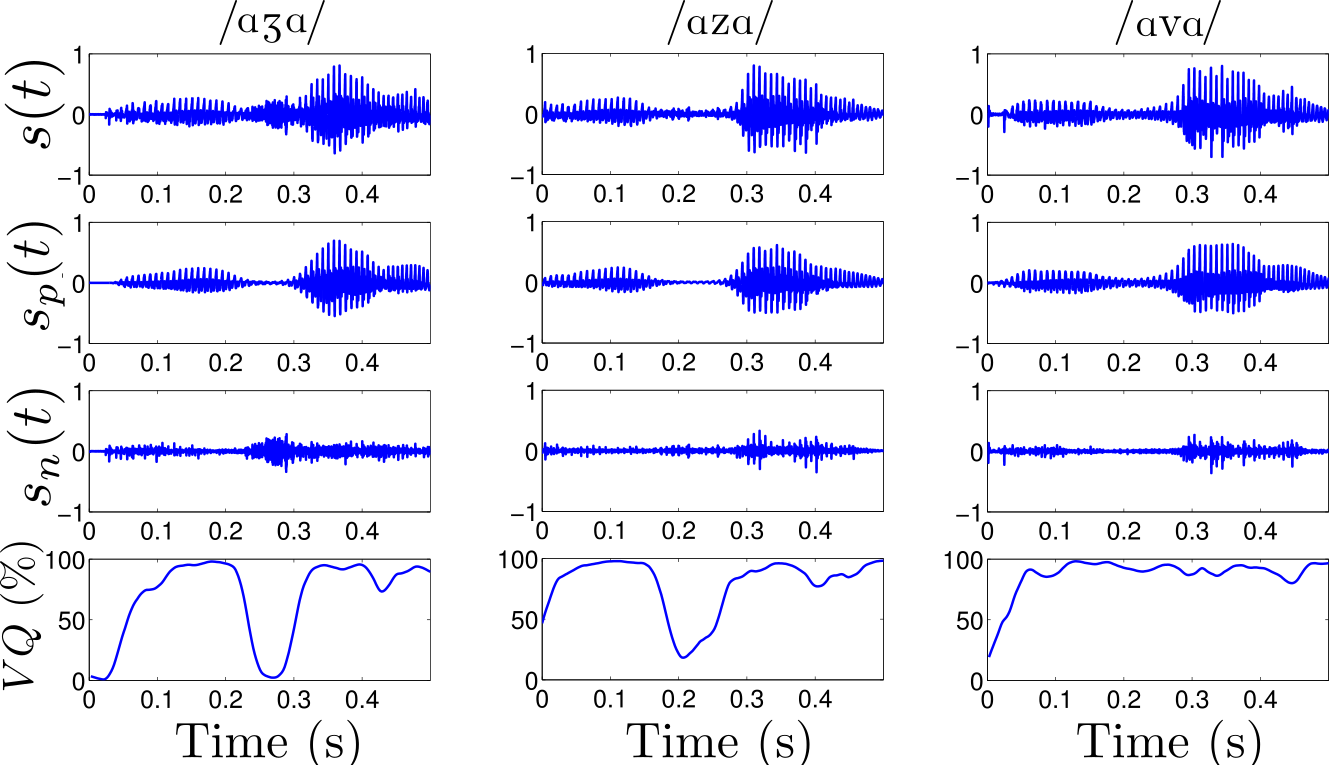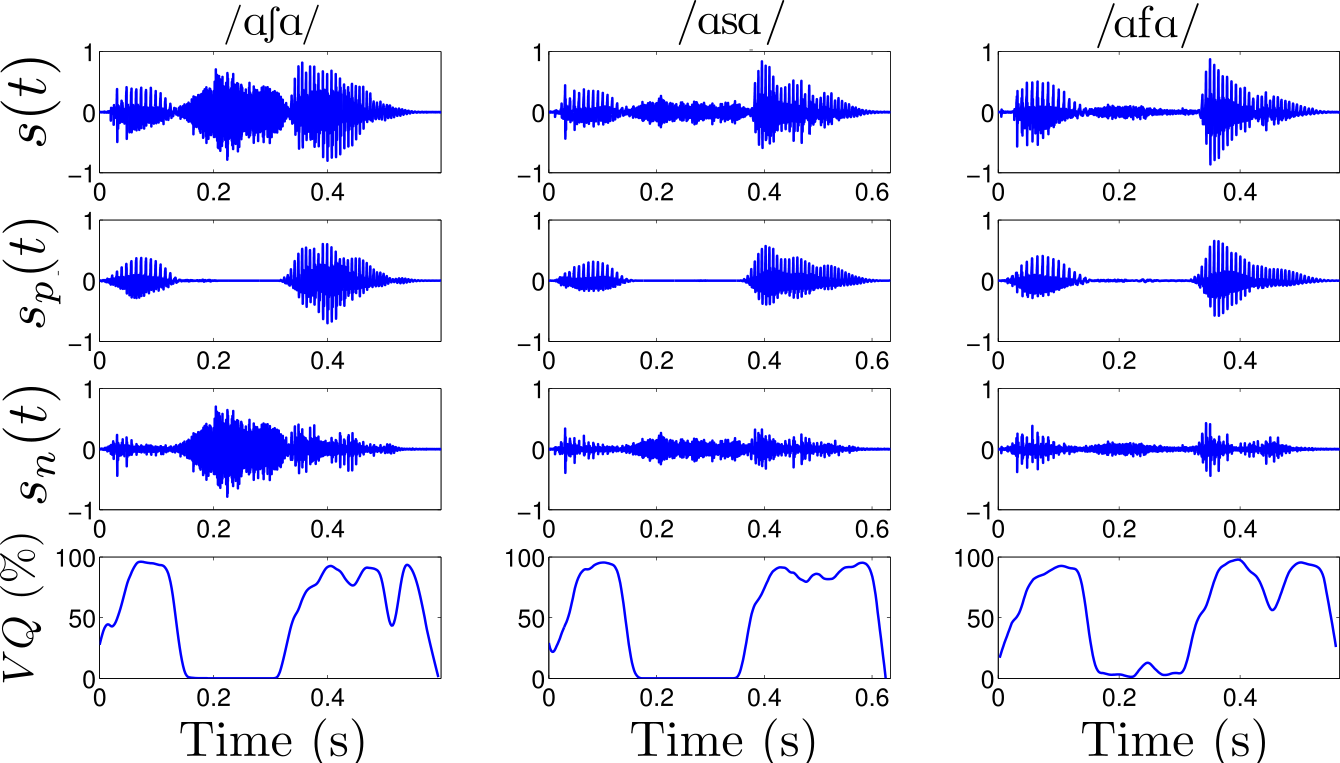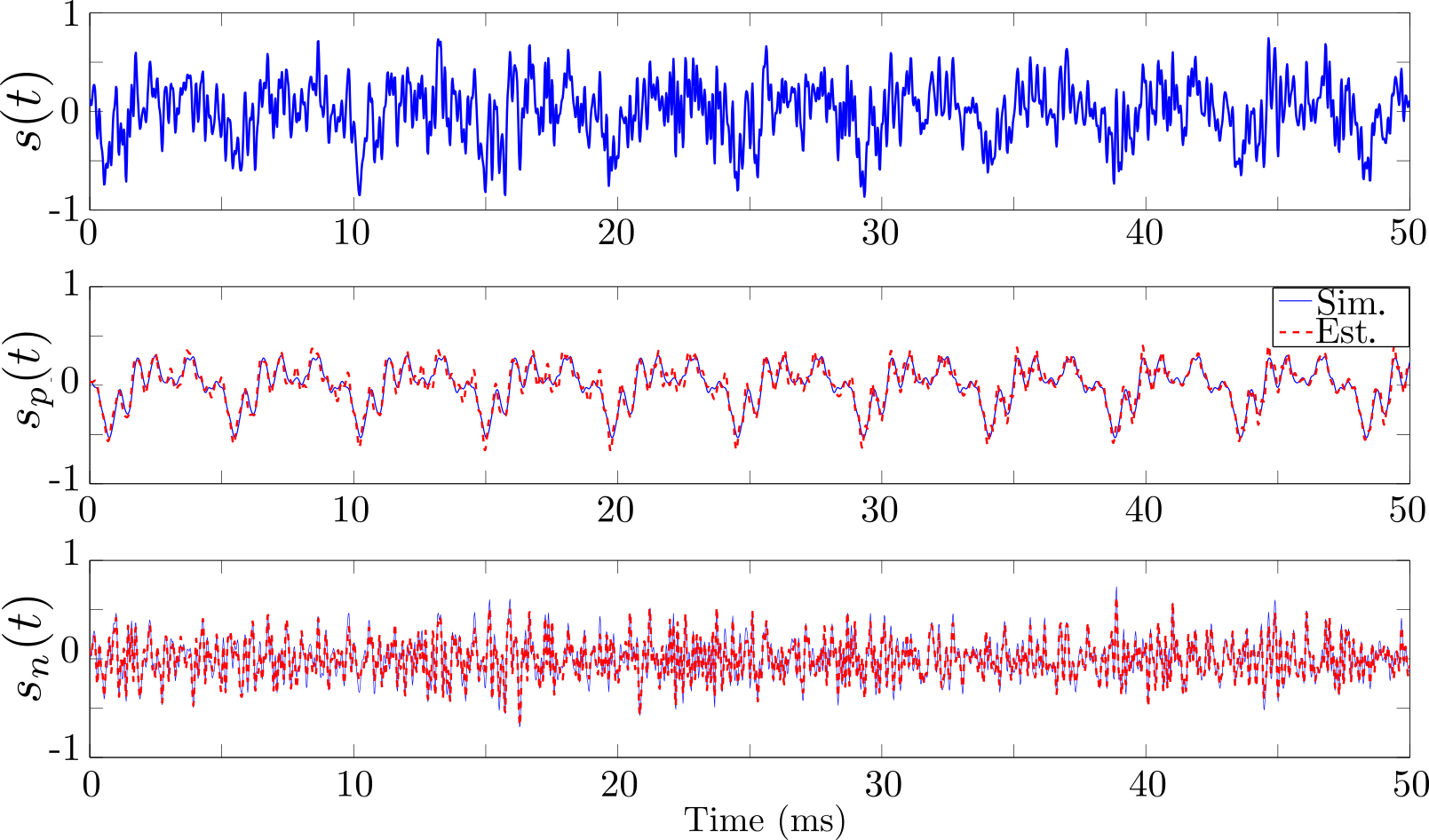
Example of separation performed on a simulated voiced alveolar
fricative /z/.
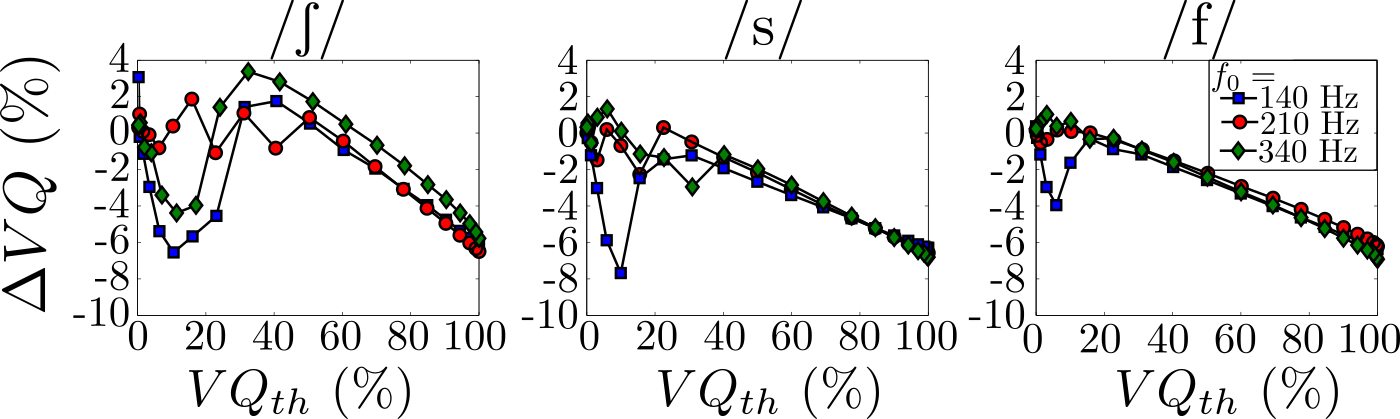
Numerical validation on simulated fricative signals for each of the
three places of articulations of French fricatives. The validation compares the
estimated voicing quotient ($VQ$) with the theoretical $VQ$.